AI in a nutshell
ML allows computers to learn tasks directly from data(datasets)
Machine learning can be said to be a subfield of AI, which itself is a subfield of computer science.
Key concept:
- ML are systems that improve their performance in a given task with more and more experience or data.
- Machine learning involves almost always some kind of statistics
Deep learning is a subfield of machine learning, which itself is a subfield of AI, which itself is a subfield of computer science.
Key concept:
- The “depth” of deep learning refers to the complexity of a mathematical model
Taxonomy of AI:
A taxonomy is a scheme for classifying many things that may be special cases of one another.
CS --> AI --> ML --> DL --> Data Science
! 200
The taxonomy scheme is composed of Euler diagrams overlapping with each others, similar to what happens with CS, AI, ML, DL, and DS
Key terminology:
- General vs Narrow AI: Narrow AI refers to AI that handles one task. General AI, or Artificial General Intelligence (AGI) refers to a machine that can handle any intellectual task.
- Strong vs Weak AI: Weak AI is what we actually have, namely, systems that exhibit intelligent behaviours despite being “mere“ computers.
This happens in 2 phases:
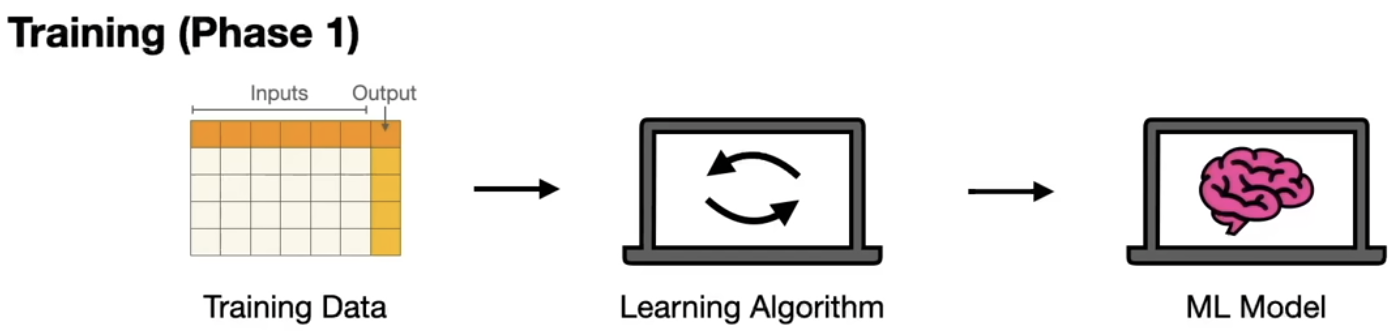
- Training dataset (set of data), passing it to a learning algorithm, the result of the algorithm is a ML model.
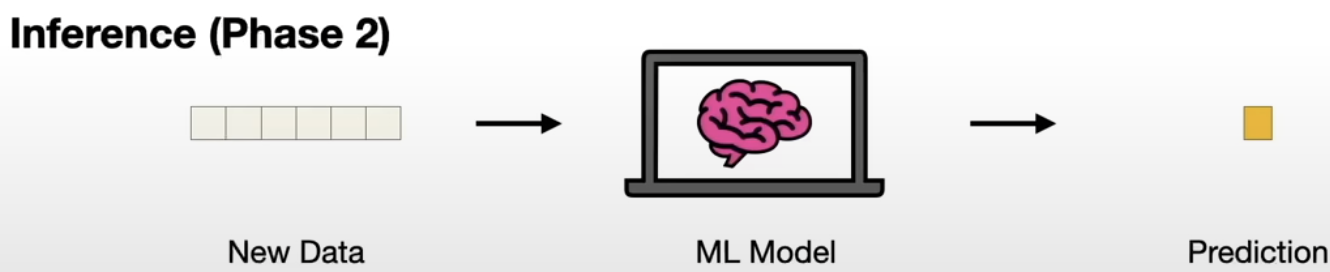
- Once we have the ML model, we can feed it new data to make predictions or solving problems.
Inference: Using a linear model to make predictions
Linear model : ! 150
When we feed data to a ML algorithm, the quality of our prediction is determined by how well the parameters are aligned with reality.
How to pick parameters for accurate predictions?
This happens during the training phase (Phase 1)
In training, we want to minimise the discrepancy between our model predictions and real-world data.
How to do it? We quantify this discrepancy, also called the loss function.
! 300
Lost function equation
By taking the difference between these actual values and the model prediction of values.
As the goal is to find parameter values that gives us the smallest loss, we can take a mathematical approach like this:
! 300
More ML techniques: Different ways to learn parameters from data
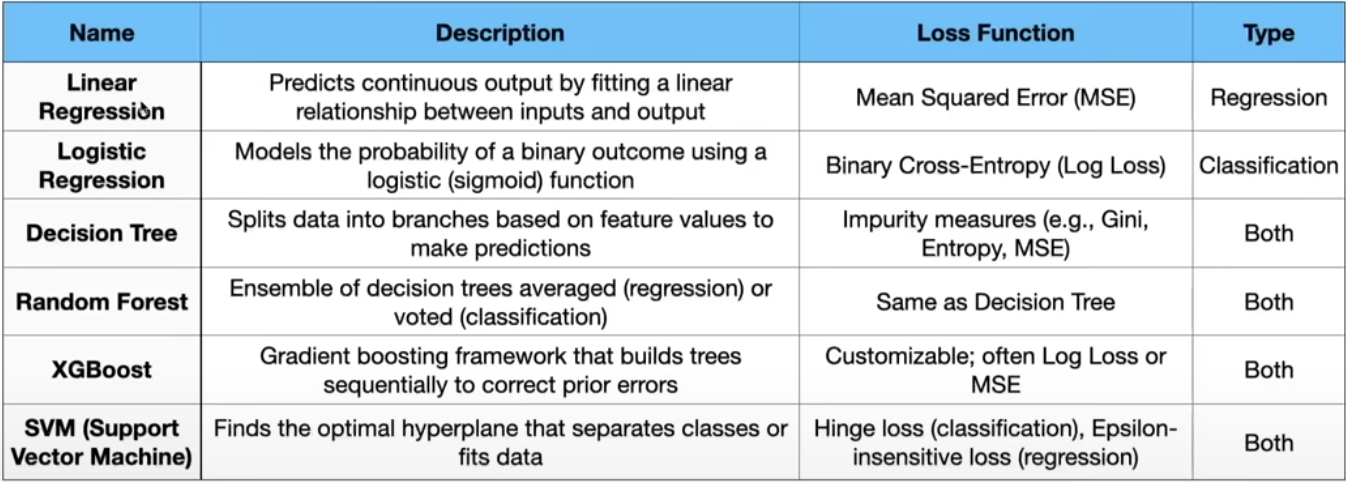
All these approaches are traditional Machine Learning Algorithms that can be used in different contexts.
The main challenge is to select the correct input variable (feature) for the model's prediction.
The process of picking the right input variable is called feature engineering.
Another way to implement AI is through Deep Learning:
One of these is the Neural Networks that learn optimal features on their own. (Remember that finding the right input feature was the main goal in traditional ML )
! 400
Deep Neural Network doing image recognition
- The raw image pixels are the input to the network.
- The early layer of the NN would represent basic features such as edges, textures, etc.
- The middle layers would represent higher-level features like eyes, ears, etc.
- The deep layers would represent high-level objects , such as a cat.
The key technique in Deep Learning is neural networks, which are a series of operations that can approximate any function.
! 400
Neuron
- Has a set of datapoints, multiply them by some corresponding weights and sum them together. It applies a biased term (a scalar value to the summation) , passes the result to a non-linear function called Activation function.
- This will give an output out of the neuron.
We can see that on the right, the equation looks a lot like the linear model. But the key difference is the activation function (g), which is a nonlinear function.
Build up a network of Neurons:
! 100
We combine a set of datapoints as a neuron
!100
Combine multiple neuron with multiple inputs to form a layer
! 200
Combine multiple layers together to form a network = Neural Network
Type of Neurons:
! 200
Type of activation functions:
! 250
Type of Layers:
! 300
Type of Network architectures:
! 250